
Nejčastější chyby v SEO

V SEO, stejně jako v jiných oborech, se na webech často opakují stejné chyby. Pokud se na ně zaměříte a vyřešíte je přednostně, velmi pravděpodobně nebudou existovat žádné zásadní překážky v úspěšné optimalizaci pro vyhledávače. Následující seznam chyb (a zejména jejich řešení) vám pomůže jako rádce v SEO pro každý stávající či budoucí web.
Špatná nebo nedostatečná indexace
Indexace je proces, pomocí kterého si vyhledávač ukládá do své paměti informace, které na webových stránkách sesbíraly specializované programy, kterým se také říká roboti - crawleři. Ti se snaží stáhnout veškerý obsah stránek a vyhledávač je ukládá do tzv. indexu (do své databáze).
Během tohoto procesu ale může dojít k technickým překážkám, kvůli kterým buď robot stránku správně nestáhne, nebo ji vyhledávač do svého indexu neuloží celou.
Kvalitní a dostatečná indexace je základem fungujícího webu. Naším cílem je, aby roboti dokázali stránku pravidelně a bez problémů procházet a vyhledávače kompletně indexovat.
Problémy crawlingu a indexace
Nejčastější překážky robotů a indexace jsou následující:
-
-
Textový obsah stránky je vypisovaný technologií, se kterou si vyhledávače nedokáží poradit (např. JavaScript, Flash, text v obrázcích, zaheslované stránky, text zobrazovaný na základě cookies atp.)
-
Stránka reaguje pomalu a nestihne vypsat obsah, než to robot vyhledávače „vzdá”.
-
Roboti mají zakázaný přístup na stránky - ať už formou nějaké zaheslované sekce nebo zákazem přístupu v robots.txt, pomocí meta značky robots nebo pomocí pokynu xrobots v http hlavičce.
-
Stránky jsou duplicitní nebo velmi podobné. Obsah vaší stránky je dostupný i na jiné URL, a vyhledávač nemá důvod indexovat duplicitní obsah.
-
Stránky jsou penalizované vyhledávači. Pokud trvale a opakovaně porušujete doporučení dané vyhledávači v jejich nápovědě, mohou vás vyhledávače penalizovat a důsledkem takové penalizace může být i vyřazení z indexu.
-
Na stránku se vyhledávač nedostane kvůli nevhodné struktuře stránek a nedostatečné práci s interními a externími odkazy. Jinak řečeno - na stránku nevedou odkazy z jakékoliv jiné zaindexované stránky.
-
Jak ověříme indexaci ve vyhledávačích?
Kolik stránek našeho webu vyhledávač indexuje, ověříme pomocí operátoru site:. Operátory jsou slova zakončená dvojtečkou, která v různých kombinacích můžeme psát do vyhledávacího políčka, čímž zpřesňujeme vyhledávání.
Syntaxe je site:vašedoména.cz. Například pro kontrolu webu Mall.cz použijeme site:mall.cz. Tento operátor funguje jak u vyhledávače Google, tak u vyhledávače Seznam. Na základě tohoto operátoru vám vyhledávače vypíší zaindexované stránky webu od nejlépe hodnocené.
V červeném rámečku na obrázku také vidíte počet všech vyhledávačem zaindexovaných stránek.
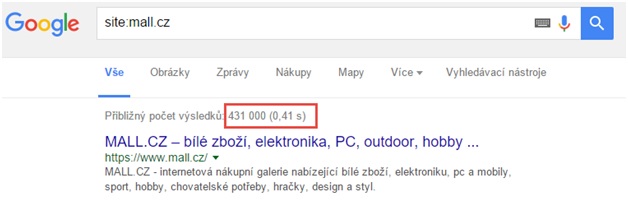
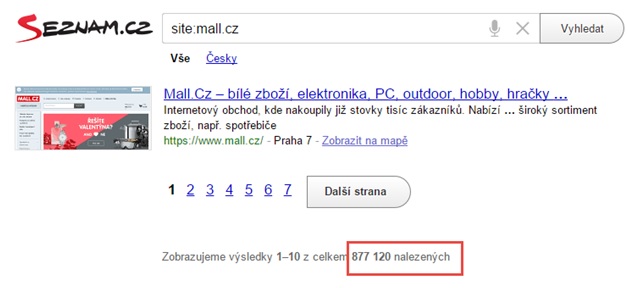 Na obrázku výše je vidět, že Google tyto informace vypisuje nahoře a Seznam naopak dole. V tomto případě je i hezky vidět, jak jednoduchým dotazem do vyhledávačů zjistíme problém v indexaci. Seznam indexuje z Mall.cz 877 120 stránek a Google jen 431 000, což je méně než jedna polovina. Může to signalizovat problém. Buď Seznam indexuje spoustu zbytečných stránek, nebo Google neindexuje velké množství stránek.
Na obrázku výše je vidět, že Google tyto informace vypisuje nahoře a Seznam naopak dole. V tomto případě je i hezky vidět, jak jednoduchým dotazem do vyhledávačů zjistíme problém v indexaci. Seznam indexuje z Mall.cz 877 120 stránek a Google jen 431 000, což je méně než jedna polovina. Může to signalizovat problém. Buď Seznam indexuje spoustu zbytečných stránek, nebo Google neindexuje velké množství stránek.
Řešení nedostatečné indexace
Za nedostatečnou indexací vždy stojí některý z problémů, který jsem shrnul v kapitole Problémy crawlingu a indexace. V této fázi je nejlepší postupně projít možné příčiny a zjistit, která z nich platí pro váš web. Podívejme se nyní na řešení nejčastějších příčin.
Nevhodná technologie
Vypněte si JavaScript (podporu Flashe aj.) v prohlížeči a zkuste procházet vaším webem. Pokud se část stránky nezobrazí, je možné, že jste narazili na příčinu problému v indexaci (viz obrázek).
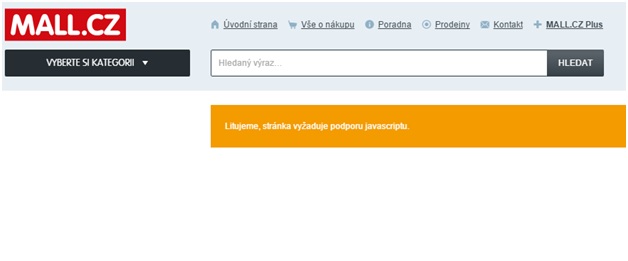
V tomto případě se jedná problém v technickém řešení, kdy web pomocí JavaScriptu vypisuje i obsah a URL dalších stránek.
Řešením je přepsat šablonu vašeho webu tak, aby i bez JavaScriptu byl web použitelný, a tím pádem i použitelný pro roboty. Vypnutím JavaScriptu se nesmí z vašeho webu stát nepoužitelný pahýl.
Duplicity na webu
S odhalením duplicit vám pomůže nástroj Google Search Console. Stejně jako Google Analytics je zcela zdarma a jako diagnostický nástroj webu z pohledu Google je velmi cenným pomocníkem při odhalování duplicit.
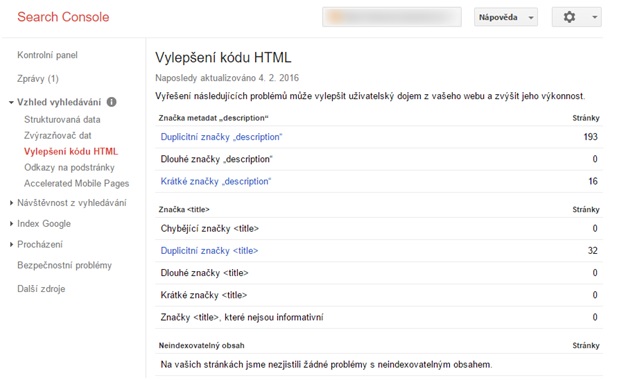
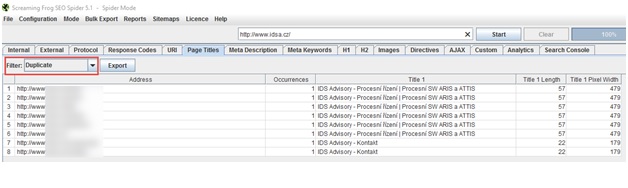
V reportu, který vidíte na screenshotu, se můžete dozvědět o stránkách, které mají duplicitní titulky a meta description. Můžete tak odhalit řadu duplicit. Podobný způsobem můžete použít i další nástroje jako Screaming Frog, Xenu nebo SEO toolkit.
 Řešení duplicit má dvě varianty:
Řešení duplicit má dvě varianty:
1. Duplicitní stránky není potřeba zachovat - duplicitní URL je třeba přesměrovat pomocí kódu 301. To můžete zařídit sami pomocí úpravy soubor .htaccess přímo na serveru nebo pomocí PHP hlavičky. Některé redakční systémy mají tuto funkcionalitu přímo zabudovanou. Pokud si nevíte rady, poproste vašeho vývojáře.
2. Duplicitní stránky jsou důležité pro návštěvníky - stránku zakážeme k indexaci pomocí meta značky robot ve zdrojovém kódu stránky: . Může také pomoci zákaz procházení v robots.txt. Je potřeba si uvědomit, že příkaz v robots.txt nezakazuje indexaci.
User-agent: *
Disallow: /url-duplicitni-stranky/
Nevhodně řešená filtrace
Filtry umožňují specifické třídění kategorií. Stránky vzniklé filtrací jsou skvělé vstupní stránky zejména pro long-tailové fráze. Nevhodné technické řešení - zejména e-shopů - však způsobuje, že tyto cenné vstupní stránky nejsou indexovány.
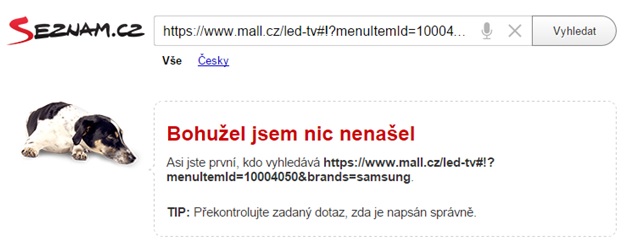
Typickým zástupcem nevhodně řešeného filtrování jsou třeba známé weby jako Alza.cz nebo Mall.cz. Stránky vzniklé filtrací mají následující URL, např. pro LED televize Samsung:https://www.mall.cz/led-tv#!?menuItemId=10004050&brands=samsung a https://www.alza.cz/televize/18849604.htm#f&cst=0&pg=1&prod=1299&sc=600.
Co si vyhledávače o těchto URL myslí, ukazuje následující screenshot:
Pro správnou tvorbu filtrace z technické stránky SEO je třeba splňovat následující podmínky:
1. Odkaz na stránky vzniklé filtrací musí být ve zdrojovém kódu stránky, a to i při vypnutém JavaScriptu.
2. Všechny varianty filtrů musí fungovat i při vypnutém JavaScriptu.
3. Stránky vzniklé filtrací musí mít unikátní URL (která nesmí obsahovat znak #).
4. Stránky vzniklé filtrací musí mít unikátní obsah, a to zejména titulky, meta description, nadpis a úvodní text.
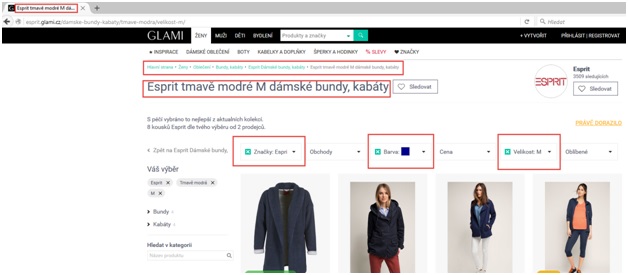
Ukázku takové filtrace najdete třeba na Glami.cz:
Na co si dát pozor?
Pokud chcete podnikat na internetu, SEO bude vždy jeden z nejdůležitějších kanálů. Výše zmíněné chyby mohou blokovat cennou návštěvnost, potažmo potenciální zákazníky. Doporučuji tuto problematiku nepodceňovat a při každé tvorbě webu i jakékoliv marketingové strategie mít k ruce kvalitního specialistu na SEO.
Hodně štěstí v získávání návštěvnosti z vyhledávačů!
![]()
 Autorem článku je Pavel Ungr, specialista na SEO a online marketing s desetiletou zkušeností v oboru. Pracuje jako konzultant na volné noze, zkušenosti sbíral i v agenturách H1.cz a Ataxo. Krom SEO ho zajímá UX, obsahový marketing a sociální sítě. Pracuje pro střední i větší klienty jako např. Lidskásíla.cz, Alkohol.cz, Karlova Univerzita, Hudy.cz, eBrána nebo zahraniční projekty jako Social Bakers či Lectura. Pavel je opravdovým nadšencem svého oboru, o kterém také přednáší a publikuje. Můžete navštívit jeho veřejná školení nebo si objednat jeho služby. O novinkách v SEO informuje na Twitteru a na svém blogu. Zájemce o SEO zaujmou i jeho projekty vyhledava.cz a SEOloger.
Autorem článku je Pavel Ungr, specialista na SEO a online marketing s desetiletou zkušeností v oboru. Pracuje jako konzultant na volné noze, zkušenosti sbíral i v agenturách H1.cz a Ataxo. Krom SEO ho zajímá UX, obsahový marketing a sociální sítě. Pracuje pro střední i větší klienty jako např. Lidskásíla.cz, Alkohol.cz, Karlova Univerzita, Hudy.cz, eBrána nebo zahraniční projekty jako Social Bakers či Lectura. Pavel je opravdovým nadšencem svého oboru, o kterém také přednáší a publikuje. Můžete navštívit jeho veřejná školení nebo si objednat jeho služby. O novinkách v SEO informuje na Twitteru a na svém blogu. Zájemce o SEO zaujmou i jeho projekty vyhledava.cz a SEOloger.
Článek je jednou z kapitol e-booku společnosti Forpsi, který vznikl s pomocí agentury RobertNemec.com a řady nezávislých odborníků.
Je určen pro všechny, kteří chtějí zlepšit výkon svých webů, i pro ty, kdo chtějí získat základní znalosti o hlavních oblastech online marketingu. 11 kapitol nabízí tento obsah:
-
-
Pavel Ungr – nejčastější chyby v SEO, kterých se majitelé webů dopouštějí.
-
Martin Šimko – na co si dát pozor při spolupráci se SEO konzultantem nebo agenturou.
-
Marie Štouračová – optimalizaci webu pro mobilní přístupy.
-
Juraj Sasko – SEO a webhosting.
-
Mário Roženský – základy affiliate marketingu pro e-shop.
-
Zdeněk Dvořák – praktické tipy a rady z oblasti budování zpětných odkazů.
-
Adam Jurák – základy e-mailingu a využití pro byznys.
-
Klára Kunová – vyhodnocování výkonnosti webu pro e-shopy.
-
Ludmila Navrátilová – praktické tipy při práci s Google Analytics.
-
David Mareček – jak lépe rozumět publiku vašeho webu a proč je důležité testování.
-
Monika Styxová – jak tvořit obsah.
-
E-book si můžete zdarma stáhnout na stránkách Forpsi.


